目录
-
-
Series
- 创建 Series对象
- 属性
-
数据访问
- 下标
- loc和iloc
-
DataFrame
- 创建⼆维ndarray对象
-
属性
- 数据操作
-
关于⼴播
- 规则
- 算数运算⽅法
- 摘要
- ⽂件读写
-
Series
pandas是Python编程语⾔的⽤于数据操纵和分析的软件库。特别是它提供操纵数值表格和时间序列的数据结构和运算操作。pandas是在三条款BSD许可证下发⾏的⾃由软件,其名字衍⽣⾃术语“⾯板数据”(panel data),这是计量经济学的数据集术语,它包括了对同⼀个体的在多个时期上的观测。
特征
-
DataFrame对象,⽤于数据操纵并具有集成的索引。
-
在内存中数据结构和不同的⽂件格式之间读写数据的⼯具。
-
数据对齐和集成的缺失数据处理。
-
数据集的再成形(reshape)和选择(pivot)。
-
⼤数据集的基于标签的分⽚、fancy索引和⼦集。
-
数据结构列的插⼊和删除。
-
按引擎(engine)分组,允许在数据集上的分离-应⽤-合并(split-applycombine)运算操作。
-
数据集的归并和连接。
-
层级轴索引,以低维数据结构⼯作在⾼维数据上。
-
时间序列-功能:数据范围⽣成和频率转换,移动窗⼝统计,移动窗⼝线性回归,数据转移(shift)和滞后(lag)。 提供数据过滤。
这个库对性能进⾏了⾼度优化,具有关键代码路径⽤Cython或C写成。
——来⾃维基百科:https://zh.wikipedia.org/wiki/Pandas
Series
定义 由⼀组数据及与之相关的数据索引组成
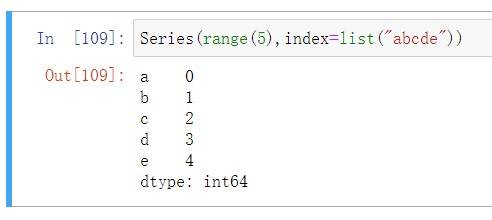
上述定义⼀个序列,指定索引为⼀个由字符构成的列表,可以看到字符和值⼀⼀对应
创建 Series对象
-
Python列表
指定索引时,索引元素需与列表元素⼀致
-
标量值
标量值创建,如未指定索引index,则默认创建⼀个元素
-
字典
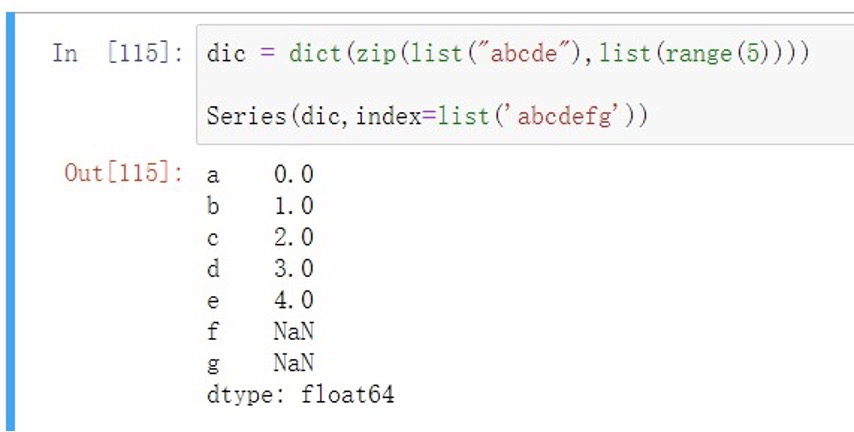
使⽤字典创建Series对象时,默认其键为索引,当然也可以指定索引,但是如果指定的索引与键不匹配,将⾃动填充NaN值
-
ndarray对象
数据值和索引皆可由ndarray创建其他函数,如range()函数
属性
.name 获取数据序列name
.index.name 获取索引name
.index 获取索引
.values 获取数据集
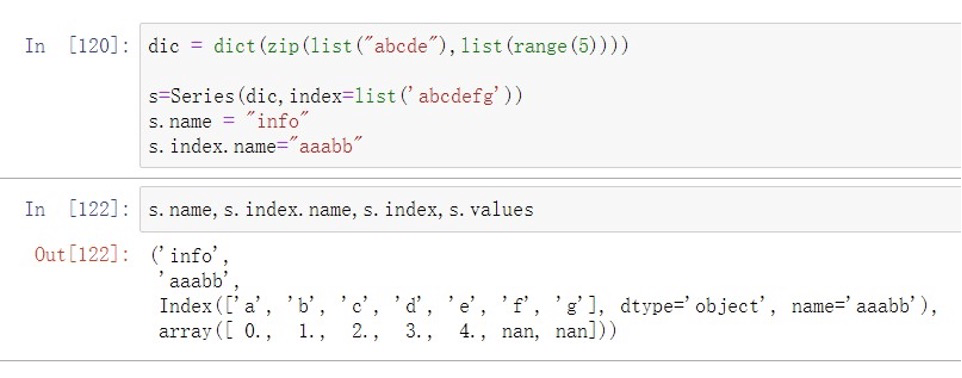
上述代码由字典创建⼀个Series对象,并设置其name,index.name等属性,然后获取其他相应属性
数据访问
下标
Series对象拥有两种索引,⾃动索引和⾃定义索引,它的操作类似数组和字典,可以使⽤切
⽚、下标、.get()等⽅式获取数据集,也可以使⽤保留字in对其遍历
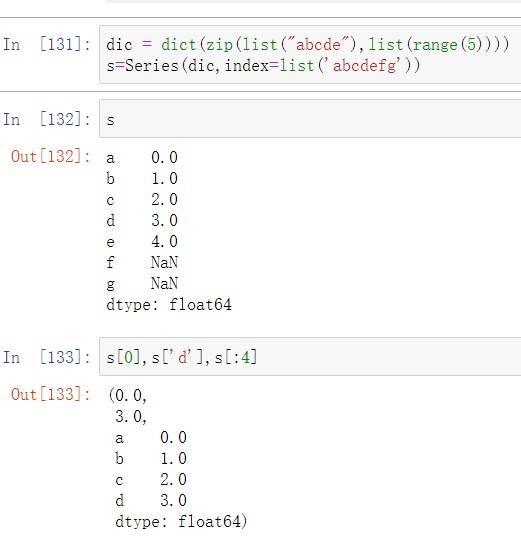
注:Series在运算时,会⾃动对其不同索引的数据,可以使⽤df[col][row]⽅法获取指定单个元素数据
loc和iloc
另外可使⽤loc和iloc选择数据
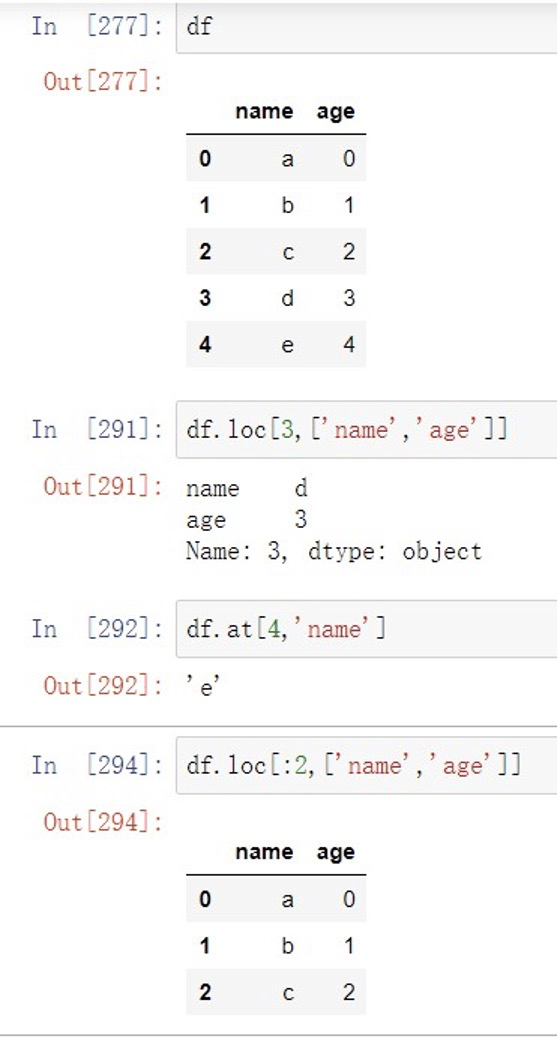
- df.loc[val] 选择单列或者多列
- df.loc[:,val] 选择单列或者多列
- df.loc[val1,val2] 选择⾏列中的⼀部分
- df.iloc[where] 根据整数选择单⾏或者多⾏
- df.iloc[:,where] 根据整数选择单列或者多列
- df.at[label1,label2] 根据标签选择单个标量值
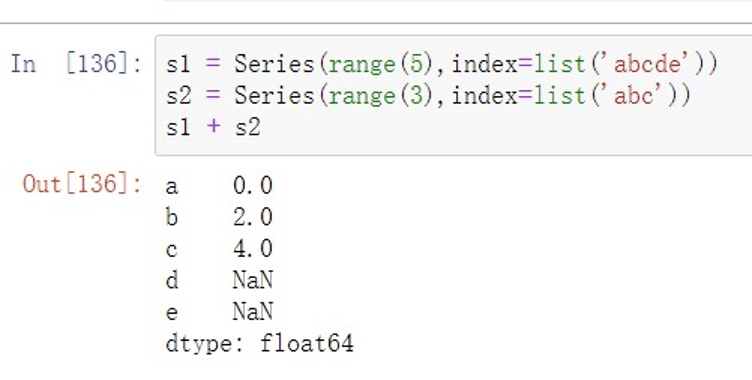
上述创建两个Series对象,后两个索引d,e没有对其,也就是s2中没有,Series会⾃动将其值填充为NaN后进⾏运算,NaN与其他数据运算结果仍未NaN
DataFrame
定义 由共⽤相同索引的⼀组列组成,它是⼀个表格型的数据,每列值类型可以不同,具有列索引和⾏索引,通常⽤于表达⼆维数据,也可表达多维数据
创建⼆维ndarray对象
由⼀维ndaaray、列表、字典、元组或Series构成的字典
-
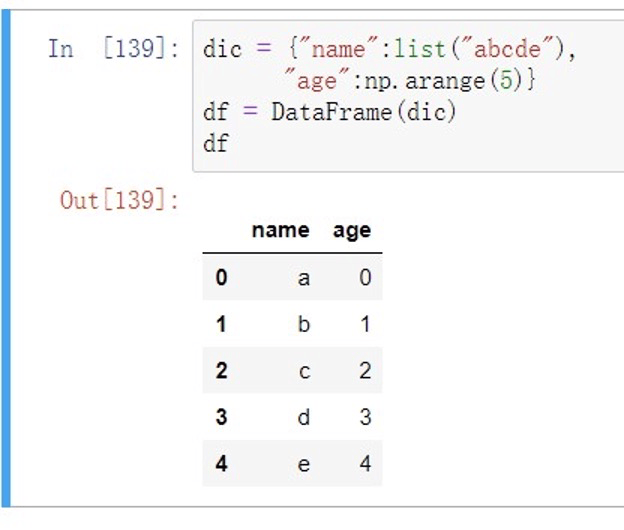
当使⽤字典创建DataFrame时,默认外层键作为列索引,内层键作为⾏索引Series对象
-
其他DataFrame
属性
index.names 返回所有索引名称 index 返回索引 columns 返回列明
数据操作
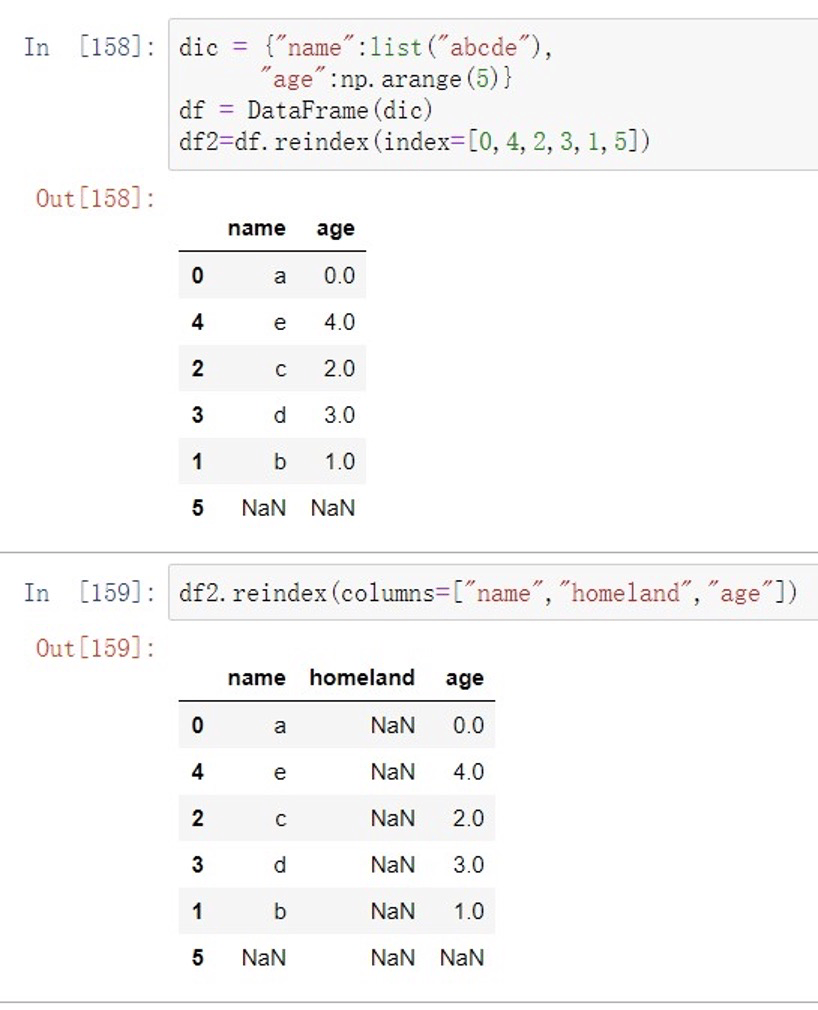
重新索引 reindex() 可以改变或重排Series和DataFrame索引
参数
- index,columns 新的⾏列⾃定义索引
- fill_value 填补缺失的值
- method 填充⽅法,ffill/bfill:先前/后填充
- limit Y⼤填充量
- copy bool ⽣成新的对象,False时,新旧相等不复制
set_index() 将⼀个列转变为索引,并创建⼀个新的DataFrame,默认情况下要转变为索引的列将被移除。
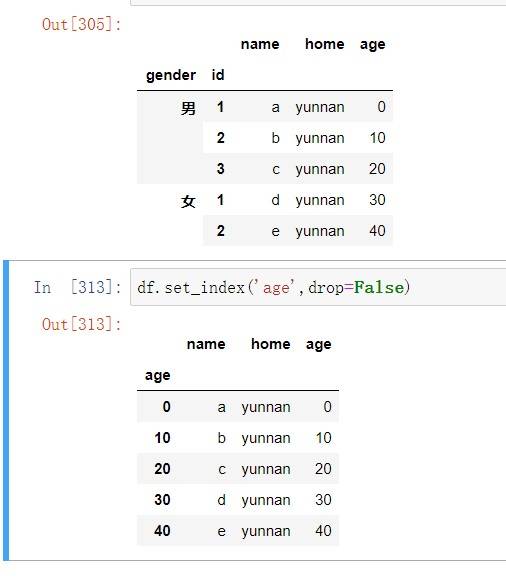
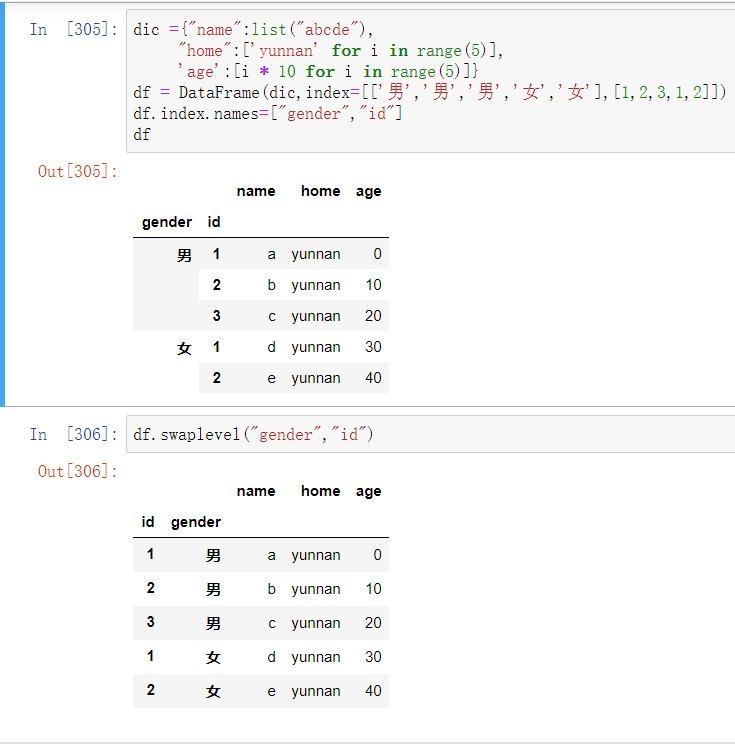
层次化索引 在⼀个轴上拥有多个索引,简⽽⾔之就是以低维度处理⾼维度数据。指定索引和列头是传⼊多个参数,当参数间标签值相同时,分为同⼀个级别。
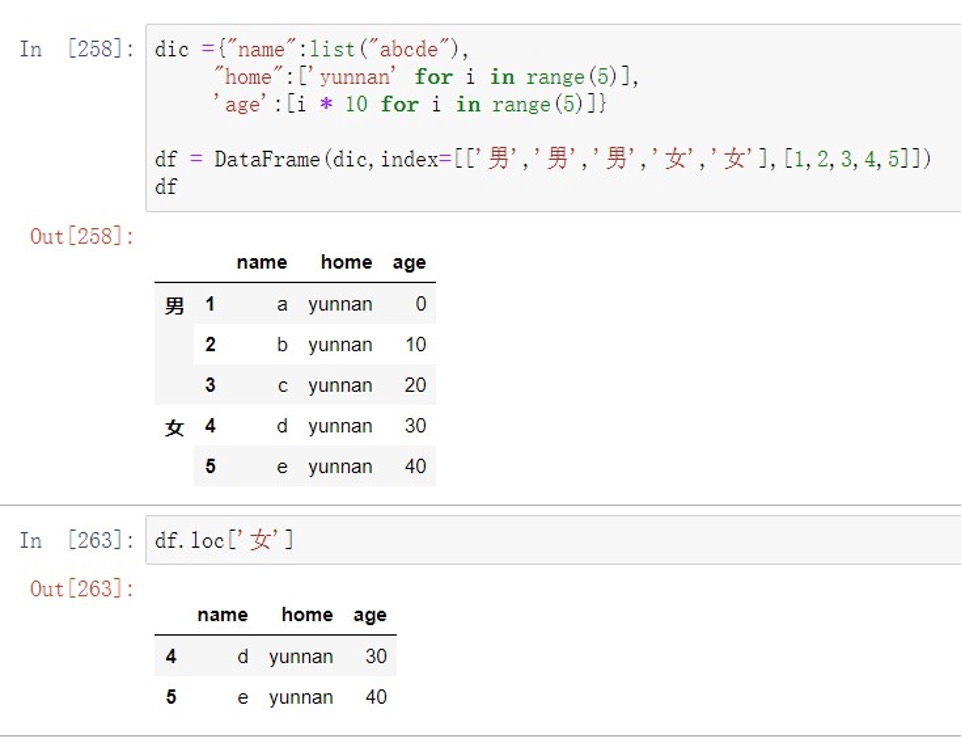
重排分级 swaplevel(class1,class2) 返回⼀个交换了级别的对象,但原数据不会改变
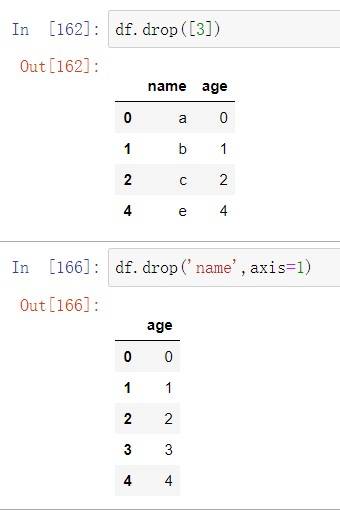
删除元素 drop()⽅法可删除指定Series和DataFrame列或⾏数据,删除列数据时,参数
axis值为1
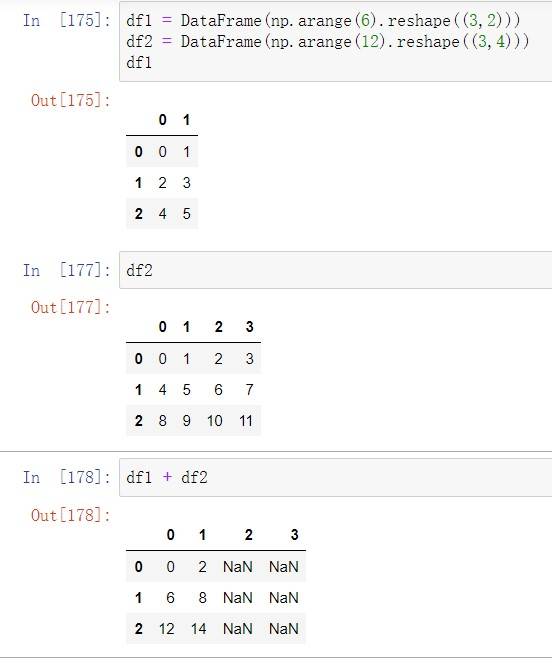
算数运算
根据⾏列索引,补⻬后运算,默认产⽣浮点数结果
补⻬是缺失项填充NaN
⼆维和⼀维,⼀维和零维间为⼴播运算
采⽤+-*/符号的⼆元运算将产⽣新的对象
关于⼴播
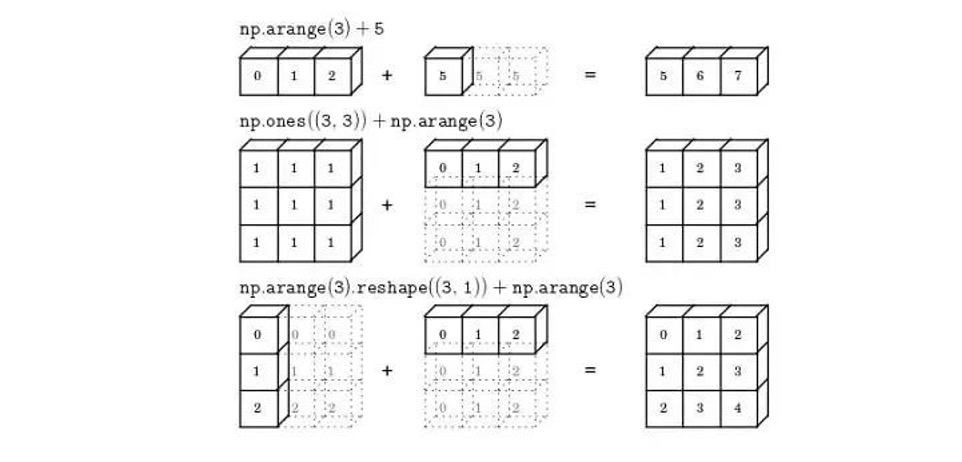
指 NumPy 在算术运算期间处理不同形状的数组的能⼒。对数组的算术运算通常在相应的元素上进⾏。如果两个阵列具有完全相同的形状,则这些操作被⽆缝执⾏。如果两个数组的维数不相同,则元素到元素的操作是不可能的。然⽽,在 NumPy 中仍然可以对形状不相似的数组进⾏操作,因为它拥有⼴播功能。较⼩的数组会⼴播到较⼤数组的⼤⼩,以便使它们的形状可兼容。
如果满⾜以下条件之⼀,那么数组被称为可⼴播的。
数组拥有相同形状。
数组拥有相同的维数,且某⼀个或多个维度⻓度为 1 。
数组拥有极少的维度,可以在其前⾯追加⻓度为 1 的维度,使上述条件成⽴
规则
如果两个数组的维度数不相同,那么⼩维度数组的形状将会在Y左边补 1。
如果两个数组的形状在任何⼀个维度上都不匹配,那么数组的形状会沿着维度 为
1 的维度扩展以匹配另外⼀个数组的形状。
如果两个数组的形状在任何⼀个维度上都不匹配并且没有任何⼀个维度等于 1,那么会引发异常。
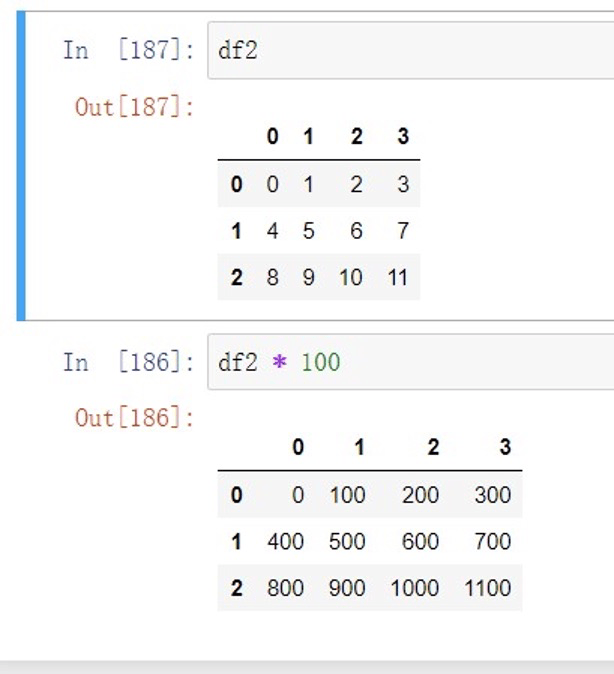
数组乘以标量也是属于⼴播
算数运算⽅法
add() 加法运算 sub() 减法运算 mul() 乘法运算 div() 除法运算
参数为df,**kwargs
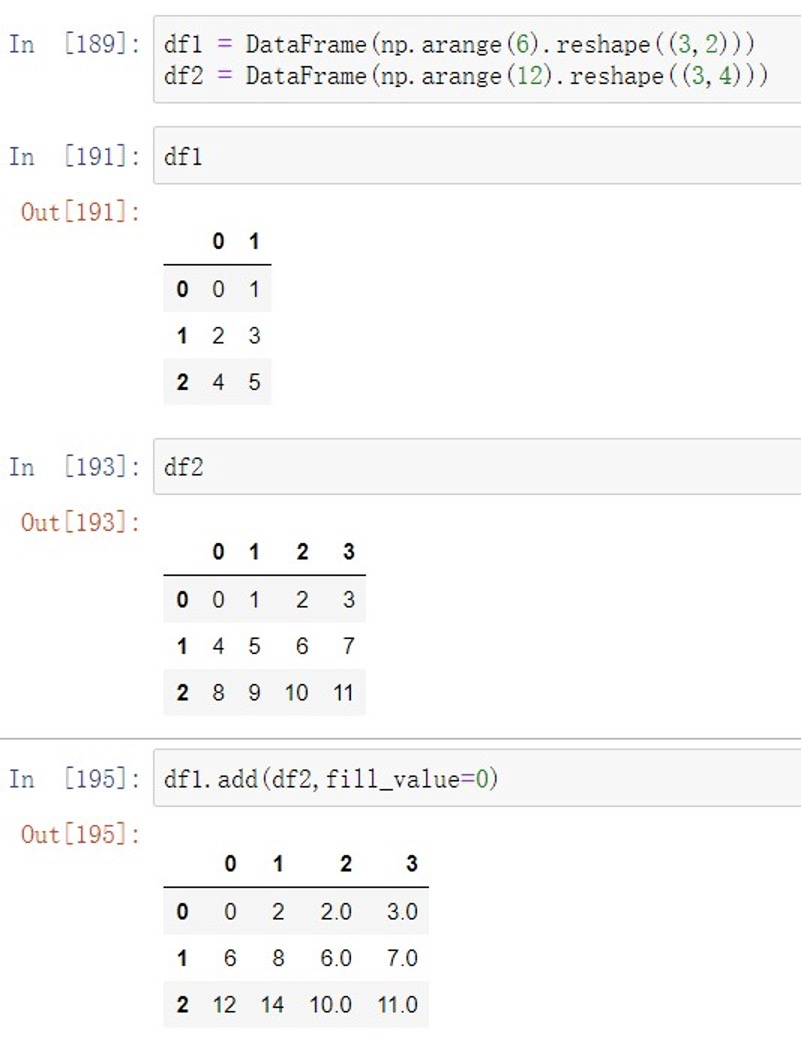
上述df1和df2进⾏相加运算,由于维度不⼀致,df1的缺失项以0填充后进⾏运算
摘要
摘要是有损地提取数据特征的过程,对于⼀组数据,对其进⾏摘要后,形成基本统计(含排序)
分布/累计统计数据特征(相关性,周期……)
数据挖掘(形成知识、经验)
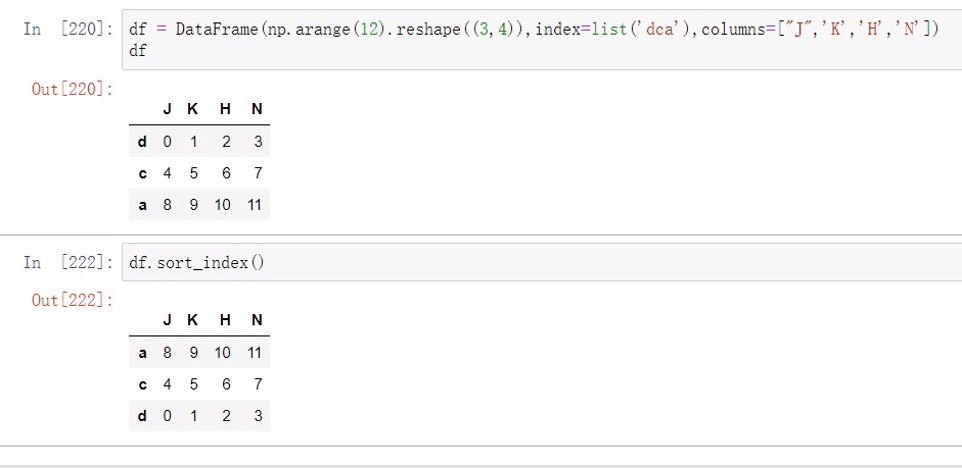
数据排序 sort_index()⽅法可在指定轴上根据索引进⾏排序
参数:
- axis 指定轴,0为⾏,1为列
- ascending bool 指定升序或降序,默认升序
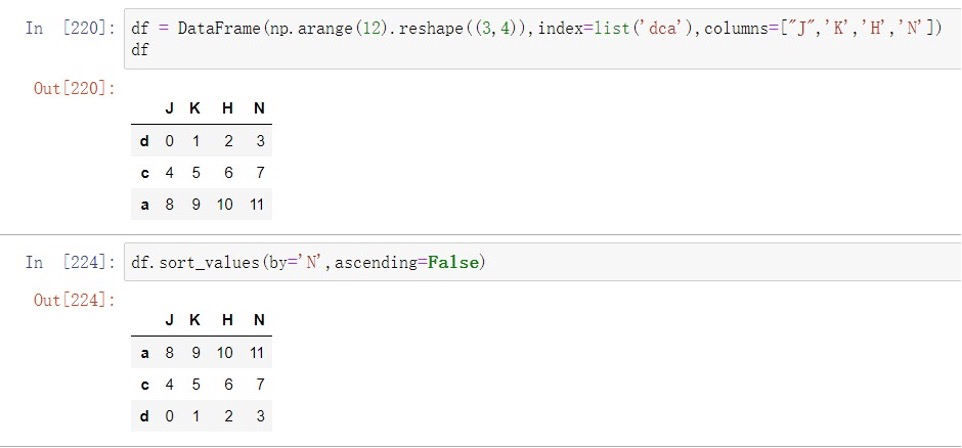
sort_values() 可在指定轴上根据数值进⾏排序,默认升序参数:
- axis 同上
- ascencindg 同上
- by 指定列/⾏
注意:以上排序会忽略NaN值,将其放置在末尾处
基本统计函数
| .sum() | 计算数据总和 |
|---|---|
| .count() | 计算⾮NaN值的数量 |
| .mean/.median() | 计算数据算数平均值、中位数 |
| .var/std() | 计算数据⽅差、标准差 |
| .min/max() | 计算数据Y⼤、⼩值 |
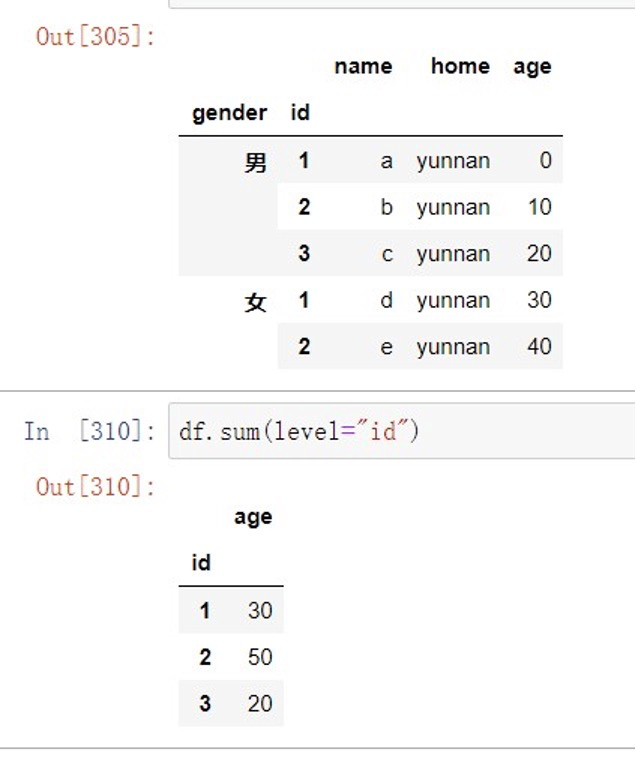
默认在0轴操作,适⽤于Series和DataFrame
可传递level级别作分组统计
| .argmin/argmax() | 计算Y⼤/⼩值所在位置的⾃动索引 |
|---|---|
| .idxmin/max() | 计算Y⼤/⼩值所在位置的⾃定义索引 |
仅适⽤于Series
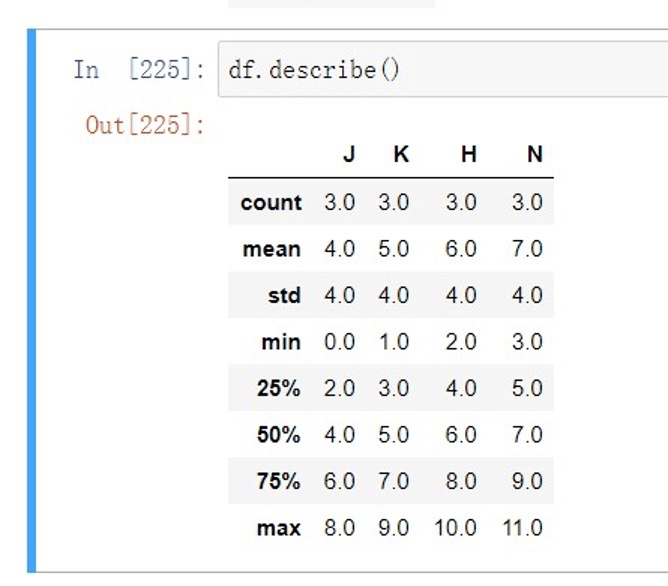
describe()⽅法可针对0轴上的数据作统计汇总(包含表⼀的所有值)
累计统计
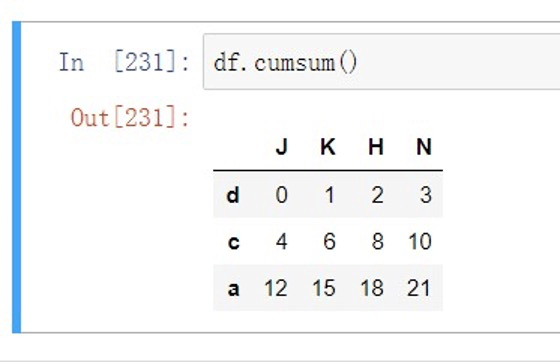
| .cumsum() | 依次给出前n个的和 |
|---|---|
| .cumprod() | 依次给出前n个的积 |
| .cummin() | 依次给出前n个的Y⼩值 |
| .cummax() | 依次给出前n个的Y⼤值 |
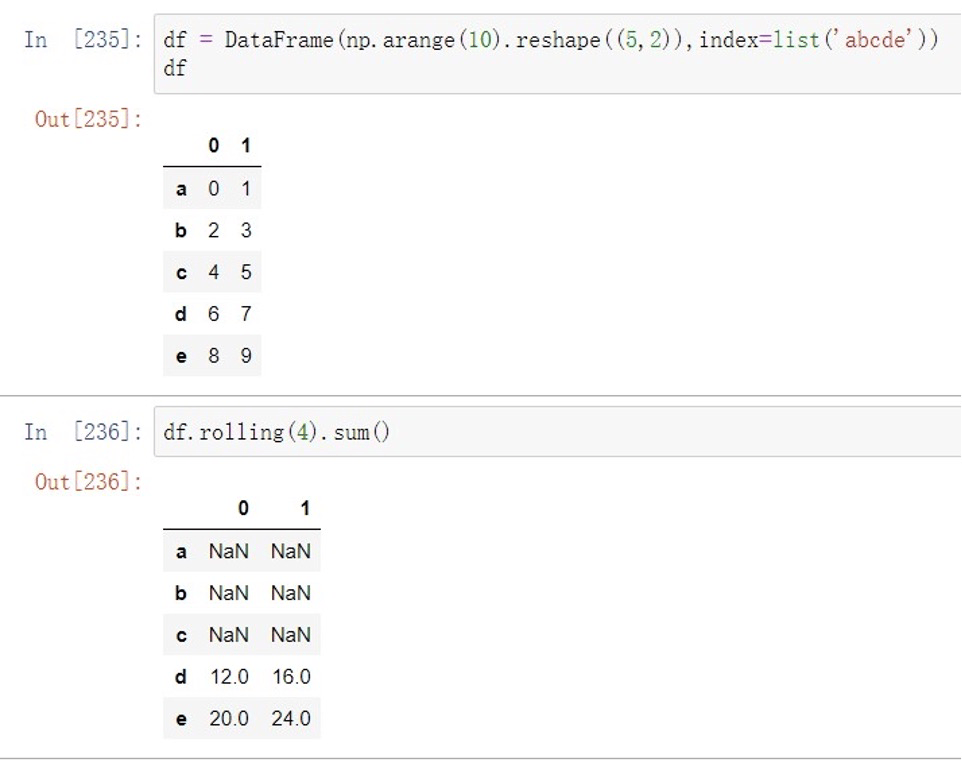
滚动计算
| .rolling(w).sum() | 依次计算相邻w个元素的和 |
|---|---|
| .rolling(w).mean() | 依次计算相邻w个元素的算术平均数 |
| .rolling(w).var() | 依次计算相邻w个元素的⽅差 |
| .rolling(w).std() | 依次计算相邻w个元素的标准差 |
| .rolling(w).min/max() | 依次计算相邻w个元素的Y⼤/⼩ |
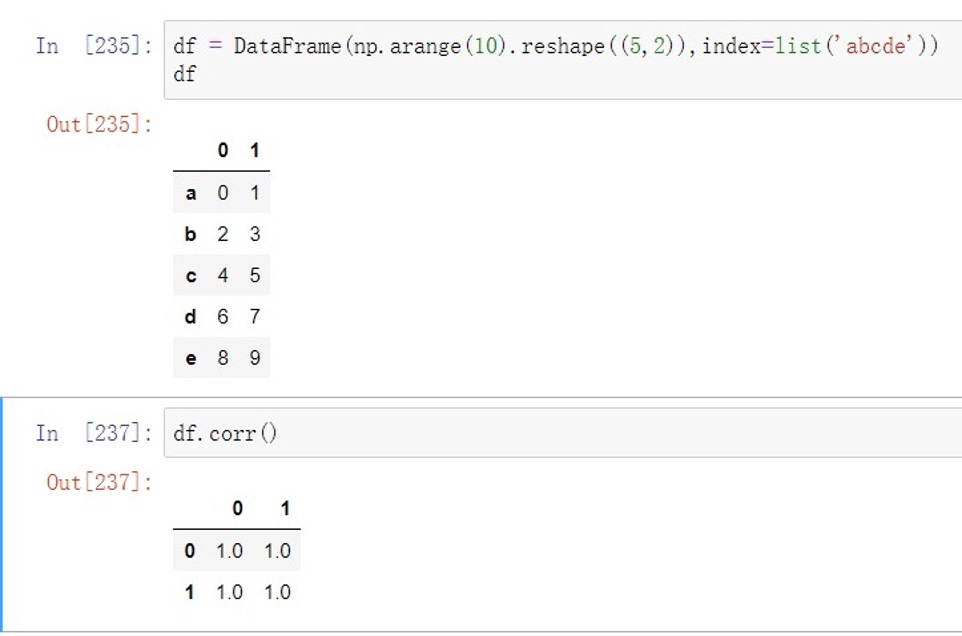
相关分析
| .cov() | 计算协⽅差矩阵 |
|---|---|
| .corr() | 计算相关系数矩阵,Pearson/Spearman/Kendall等系数 |
⽂件读写
pandas提供read_csv、read_table、read_fwf以及read_clipboard函数读取数据,但在这
⾥我主要记录如何读取csv⽂件
read_csv() 从url、⽂件、⽂件型对象中读取带有分隔符的数据,默认分隔符为逗号','
参数
- path 指定读取⽂件的绝对路径
- header 指定列明,为None时pandas将⾃动分配
- nrows 指定读取列数
- index_col 指定索引,传⼊列表时将此件层次化索引
- skiprows 指定跳过⾏
- na_values 指定缺失值的字符串,也可⽤字典
- chunksize 逐块读取
df.to_csv() 将数据写⼊csv⽂件
参数
- path 同上
- sep 分隔符
- na_rep NaN值替换字符
- index bool是否写⼊索引
- headr bool是否写⼊列头
- cols 指定写⼊列
参考资料
北京理⼯⼤学.嵩天.Python数据分析与展示
https://zh.wikipedia.org/wiki/Pandas
徐敬⼀.利⽤Pyhton进⾏数据分析[M].机械⼯业出版社.2018
Wes McKinney,Pandas Development Team.pandas:powerful Python data nanalysis toolkit[DK].2021-02-09